




Did you know that you can actually get any information or data that is publically available on the internet with a lot of ease using various scraping techniques?
Web scraping allows us to achieve this with ease using automation and some little programming basics!
I have written quite a number of articles about this topic but I have never fully done a beginner's introduction and so, today's session might be a lengthy one. Buckle up!
There are quite a number of reasons why you would want to perform web scraping and Python has a bunch of alternative solutions to handle web scraping.
 Today we are going to learn what exactly web scraping is with a hands-on session using Scrapy and we can't continue without clearly defining what web-scraping is.
Today we are going to learn what exactly web scraping is with a hands-on session using Scrapy and we can't continue without clearly defining what web-scraping is.
🔹 What is Web Scraping?
Web Scraping has a lot of nicknames like data scraping, web data extraction etc. The idea is, it is the method used to pull the data from the websites into usable formats.
From the above, we can deduce that web scraping is an automated method or technique used to extract large amounts of data from websites.
If you have ever manually copied & pasted data from a web page to a text editor, you carried out a basic form of web scraping.
🔹 Why Perform Web Scraping?
Web pages are built using text-based mark-up languages (HTML and XHTML), and frequently contain a wealth of useful data in text form.
If you want to obtain fresh web data and turn it into a valuable asset for your business, web scraping is the best way to make scalable data requests more productive.
 Some of the use-cases;
Some of the use-cases;
📌 Price Comparisons
📌 Service Providers
📌 Product Information
📌 Weather Information
📌 Research and Development
📌 Job Listings
📌 Email address gathering:
And many other related use cases, the data collected can later be dumped as JSON, CSV, text etc for more analysis, machine learning etc.
🔹 Is Web Scraping illegal?
Scraping public data has always been somewhat of a grey area. In 2019, LinkedIn lost a case by trying to argue that it could prevent the scraping of public LinkedIn profile data under their Terms of Service.
Large websites usually use defensive algorithms to protect their data from web scrapers and to limit the number of requests an IP or IP network may send. This has caused an ongoing battle between website developers and scraping developers like me.
It is most certainly illegal to analyze, change, manipulate data or sell it to someone else and also be careful while scraping especially if you have ill intentions about a particular website.
Some websites allow web scraping and some don’t and this takes me to the robots.txt file!
🔹 What is a robots.txt file?
robots.txt is a text file that tells crawlers, bots, or spiders if a website could be or how it should be scrapped as specified by the website owner. It is critical to understand the robots.txt file to prevent being blocked while web scraping.
 To know whether a website allows web scraping or not, you can look at the website’s
To know whether a website allows web scraping or not, you can look at the website’s robots.txt file. You can find this file by appending /robots.txt to the URL that you want to scrape.
For this article, we are scraping the Investing.com website. So, to see the robots.txt file, the URL is investing.com/robots.txt
This particular part of the website has a list of all cryptocurrencies that load dynamically with infinite scroll but today we shall only get the top 100!
Let's consider this example;
User-agent: *
Disallow:
The above example allows any spider (User agent) to access everything (Disallow == True) on the website! If Disallow is like this Disallow: /, it means we are not allowed to scrape its content!
In the Disallow field, you can also specify content that you do not allow if you are a website owner like our website.
🔹 Scraper Tools & API's
There are lots of tools out there built by developers to simplify the process of web scraping like ParseHub, Octoperse, Mozenda, Scraper API, Webhose, Diffbot etc.
All these tools provide an abstract user interface and some give you free trials and limit what you can achieve if you are not on their premium packages and that's why we are building our own spider today!
#Ad
ScraperAPI is a web scraping API tool that works perfectly with Python, Node, Ruby, and other popular programming languages.
Scraper API handles billions of API requests that are related to web scraping and if you used this link to get a product from them, I earn something.
🔹 Python Tools
I fell in love with Python because of its vast tools, community and libraries available for almost everything you want to do and I love scraping with Python too.
Scrapy, Selenium and Beautiful Soup are the most widely used web scraping frameworks written in Python. As I aforementioned, we shall focus on Scrapy in this article and we shall scrape

Please Note: In this article, I will assume that you know some basics about HTML, CSS & Python!
🔹 Intro to Scrapy
Scrapy is a high-level web crawling and web scraping framework and one of the most popular and powerful Python scraping libraries.
It takes a batteries included approach to scraping, meaning that it handles a lot of the common functionality that all scrapers need! So developers don’t have to reinvent the wheel each time.
Installation
pip install scrapy
If you have any issues with installation, please refer to the official guidefor more help!
Check if installed by opening a new command prompt and typing scrapy and please note that I am using a Windows machine.
You will see the following available methods in the output.
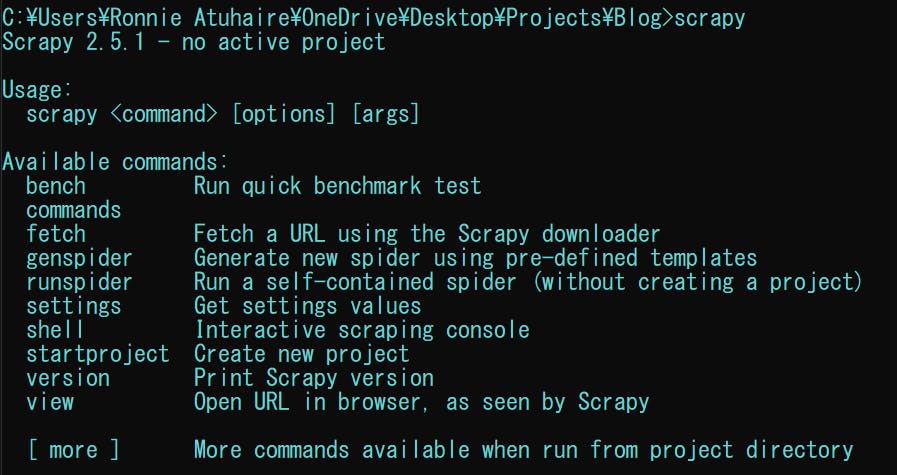
If scrapy is not recognised, you may want to add it to the path variables, consider reading the official guide and this article in order to have it recognisable.
Now let's play around with some of the major commands;
In the terminal type;
scrapy view https://www.investing.com/crypto/currencies
The above script will open that URL in a new tab from your default browser
scrapy fetch https://www.investing.com/crypto/currencies
The above script will return an HTML document in the command line
scrapy startproject crypto_scraper
The above script initialises a new project and boilerplate code and today, we want to keep things simple by building our own spider through subclassing and inheritance.
🔹 What are spiders?
Spiders are classes that you define and Scrapy uses to scrape information from a website (or a group of websites).
They must subclass Spider and define the initial requests to make, optionally how to follow links in the pages, and how to parse the downloaded page content to extract data.
Now let's create a new python file and you can name it anything you want. I will name mine crypto_list_scraper.py
Start by importing scrapy & csv
import scrapy
import csv
We could have used the inbuilt CSV service in Scrapy if we had not decided to build our custom spider.
The CSV module will help us to write to a file and we import scrapy so that we can use the classes that the package provides.
Now create a new class with the following variables & it inherits from Spider Class;
class CryptoScraper(scrapy.Spider):
name = 'crypto_spider'
start_urls = ["https://www.investing.com/crypto/currencies"]
output = "crypto_currencies.csv"
As you can see, in the custom class we have created, subclasses from the Spider class to inherit all the methods.
💨 The name variable is for the spider name we are creating.
💨 The start_urls a list of URLs that we shall start to crawl from. We’ll start with one URL.
💨 The output is where we shall write our scraped data
Let's initialise our output folder so that we are able to write to our output file.
def __init__(self):
open(self.output, "w").close()
The__init__function is called every time an object is created from a class and passes the scraped data within the same class to the referenced output.
The open() with w helps us to write to the output file which is referenced as self & close() help us in memory control of the opened file.
Scrapy has parse(): a method that will be called to handle the response downloaded for each of the requests made. The response parameter is an instance of TextResponse.
So before we define our parse method, let's do some web inspection to see which data are we going to collect and wherein the DOM does this data reside.
Like many websites, the site has its own structure, and form, and has tons of accessible useful data, but it is hard to get data from the site as it doesn’t have a structured API.
So from the website, let us only collect four major items of the crypto currencies.
📌 Rank
📌 Name
📌 Symbol
📌 Market Cap
The rest of the data available is more dynamic. Let's inspect our targeted website by selecting inspect (dev tools) when you right-click under the elements tab;
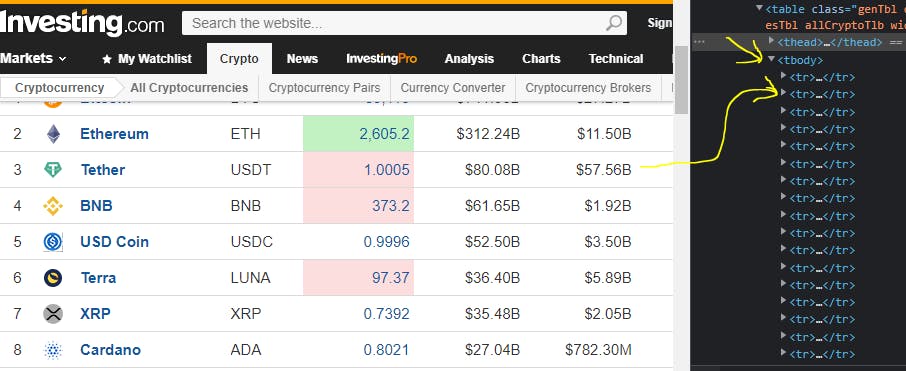
So when you use the selector to identify the structure, we see that the data we need resides in a table >> under <tbody>(table body) tag then <tr> (table row) tag
Let's get the particular tags underneath (You can ctr + shift + c):
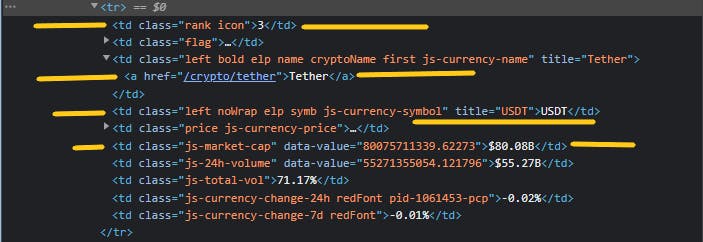
From the inspection above, we can confidently conclude the following tags have this respective information.
📌 Rank -> td > class='rank icon'
📌 Name -> td > a
📌 Symbol -> td > class='left noWrap elp symb js-currency-symbol'
📌 Market Cap -> td > class ='js-market-cap'
td is basically table data.
Since we have all the information we need, let's test get coding again. Let's add our parse method.
def parse(self, response):
crypto_body = response.css("tbody > tr")
with open(self.output, "a+", newline="") as coin:
writer = csv.writer(coin)
We have already seen from the above where our targeted data is hence crypto_body
Let's also open our file by using with statement which automatically takes care of closing hence good for resource management and exception handling.
The a+ Opens a file for both appending and reading by opening it as coin, then we use csv.witer() to append our newline.
In Scrapy, there are mainly two types of selectors, i.e. CSS selectors and XPath selectors.
Both of them perform the same function by selecting the same text or data but the format of passing the arguments is different.
CSS Selection: Since CSS languages are defined in any HTML File, we can use their selectors as a way to select parts of the HTML file in Scrapy.
XPath Selection: It is a language used to select Nodes in XML documents and hence it can be used in HTML Files too since HTML Files can also be represented as XML documents.
In the same indentation, we add the following code that I will explain later;
import scrapy
import csv
class CryptoScraper(scrapy.Spider):
name = 'crypto_spider'
start_urls = ["https://www.investing.com/crypto/currencies"]
output = "crypto_currencies.csv"
def __init__(self):
open(self.output, "w").close()
def parse(self, response):
crypto_body = response.css("tbody > tr")
with open(self.output, "a+", newline="") as coin:
writer = csv.writer(coin)
for crypto in crypto_body:
RANK = ".//td[@class='rank icon']/text()"
NAME = "td > a ::text"
SYMBOL = ".//td[@class='left noWrap elp symb js-currency-symbol']/text()"
MARKET_CAP = ".js-market-cap::text"
We used a for loop to get each coin (table row) but this time we called it crypto and
created variables for the different data that we need and used Scrapy selectors to identify and select them.
We use XPath selectors on RANK & SYMBOL with their respective classes and the text()extracts all text inside nodes' XPath response.
We used CSS Selectors on NAME & MARKET_CAP. With NAME, we used child tag a from the parent node td and appended ::text to extract the text and we used a class on the MARKET_CAP
Our entire file looks like that so far, so let's test and see. Open your terminal and cd where your file is and type;
scrapy runspider crypto_list_scraper.py
You will get something similar which does not actually do much but at least we have 200 HTTP status
 Continued image output
Continued image output
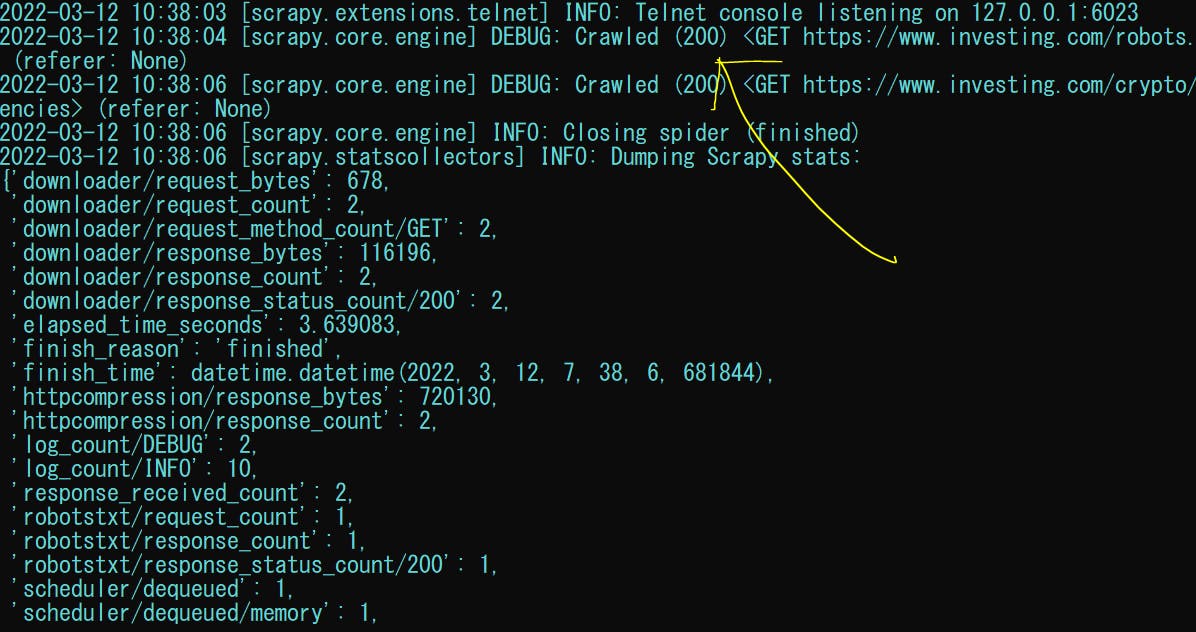
So you realise when you run that, the output file (crypto_currencies.csv) is created in the same folder which has nothing so far because we need to write the real output data to it. So delete it for now.
Let's finish up our Spider by adding this exactly under the last variables we created;
COINS = dict()
COINS["rank"] = crypto.xpath(RANK).get()
COINS["name"] = crypto.css(NAME).get()
COINS["symbol"] = crypto.xpath(SYMBOL).get()
COINS["market_cap"] = crypto.css(MARKET_CAP).get()
writer.writerow([COINS["rank"], COINS["name"],\
COINS["symbol"], COINS["market_cap"]])
yield COINS
Scrapy offers an inbuilt way of saving and storing data through the yield keyword.
So we created a COINS empty dictionary since we yield dictionary data that can easily be converted to JSON, CSV etc We are also creating new keys which we are passing on to our dictionary, looping through each coin (crypto) and the respective selector and adding get() method to it.
The method .get() returns the first item the selector found as a string.
The writer.writerow() writes a single row at a time.
And lastly, we yield our dictionary items.
Here’s our full code.
import scrapy
import csv
class CryptoScraper(scrapy.Spider):
name = 'crypto_spider'
start_urls = ["https://www.investing.com/crypto/currencies"]
output = "crypto_currencies.csv"
def __init__(self):
open(self.output, "w+").close()
def parse(self, response):
crypto_body = response.css("tbody > tr")
with open(self.output, "a+", newline="") as coin:
writer = csv.writer(coin)
for crypto in crypto_body:
RANK = ".//td[@class='rank icon']/text()"
NAME = "td > a ::text"
SYMBOL = ".//td[@class='left noWrap elp symb js-currency-symbol']/text()"
MARKET_CAP = ".js-market-cap::text"
COINS = dict()
COINS["rank"] = crypto.xpath(RANK).get()
COINS["name"] = crypto.css(NAME).get()
COINS["symbol"] = crypto.xpath(SYMBOL).get()
COINS["market_cap"] = crypto.css(MARKET_CAP).get()
writer.writerow([COINS["rank"], COINS["name"], COINS["symbol"], COINS["market_cap"]])
yield print(COINS)
So we added a print() statement on yield COINS and now let's run our project code without showing logs in the terminal.
scrapy runspider crypto_list_scraper.py --nolog
Output:
 You can find the full source code and CSV file here.
You can find the full source code and CSV file here.
🔹 Summary
This was quite a lengthy one and you learned about web scraping practically by building a simple custom Spider that retrieves crypto data from a site.
Obviously, there is more you can do with Scrapy especially when you create or start a project and in the near future, we can also learn how to create one.
I have other articles where I use Selenium, Beautiful Soup & Requests to scrape the internet. You can visit them to see other scraping Python techniques.
🔹 Conclusion
Once again, hope you learned something today from my little closet.
Please consider subscribing or following me for related content, especially about Tech, Python & General Programming.
You can show extra love by buying me a coffee to support this free content and I am also open to partnerships, technical writing roles, collaborations and Python-related training or roles.
 📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂
📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂