




Hey 👋, am glad that you are here, today I want to share with you how I scraped over 8,000 pages of Jumia Real Estate deals with just around 20 lines of Python code 🙌!
Yeah, this is very possible with Python and that's one of the reasons I fell in love with the language. If you have read about the Zen of Python, then you know what I am talking about!
Wait a minute, what is Jumia❓
Jumia is an online marketplace for electronics, and fashion among others targeting several African countries.
So Let's get started!
Before coding, I had to first determine which data do I need to mine.? So I went to the website in my chrome and had to inspect it for the tag that I will later need in my python code.
To access developer tools, just press ctr + shift + i at the same time or left click and click on inspect.
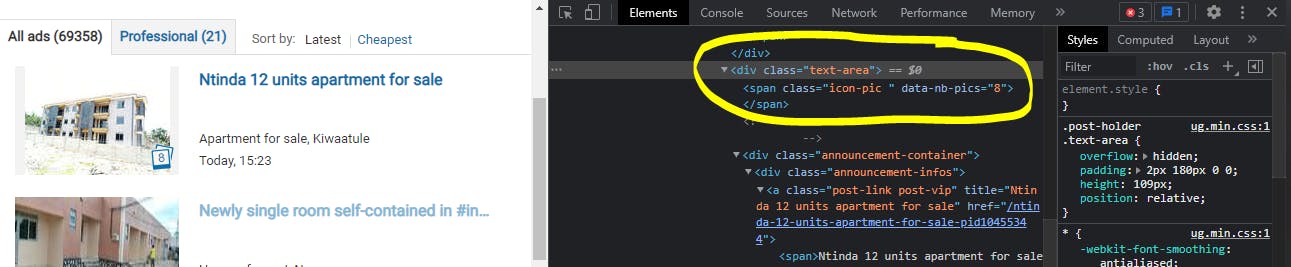
As you can see in the aforementioned picture, the information I need resides in div under a class name of text-area. By sampling a few, that tells me that all are in the same CSS class. The name is sensitive!
Let's code >>>>
# libraries I used
bs4 -> parsing HTML and XML documents
pandas -> data manipulation and analysis
os -> interacting with the operating system
requests -> elegant & simple HTTP library for Python
Just pip install - the package name in the terminal if you are coding with me.
I created a jumia_deals.py file.
Import necessary packages
import os # May Not use this
import pandas as pd
from bs4 import BeautifulSoup as beauty
import requests
Created a variable for my home URL
url = 'https://deals.jumia.ug/real-estate'
Since Jumia deals - real estate has 8,670 pages of data, I created a variable for all the URLs and used a for loop to pick data one page at ago.
all_urls = []
for page in range(1,8670):
next_urls = url + '?page=' + str(page)
all_urls.append(next_urls)
Of course, there is an alternative way without knowing the number of pages in range. I will leave that to you to figure it out 😜
The next_urls variable is for modifying pages in that range so as to have a meaningful and correct URL automatically. Found out this by sampling a few pages in range.
Implementing Beautiful Soup & Requests:
Now let's loop through our URLs and use get() from the requests library to create a connection and read the URL. For the rest of the explanation see comments in code.
for url in all_urls:
render = requests.get(url)
# print(render)
the_html = beauty(render.content, 'html.parser')
# print(the_html)
# this will help identify data under the class
# we found out in the first step -> text-area
# -> So we are Mining
scrape = the_html.find_all(class_="text-area")
# print(scrape) # If you want to log results here
# Note that we use class_ in bs4 coz python has a class keyword.
# Create a variable to store the scraped data
scraped_data = []
for data in scrape:
scraped_data.append(data.get_text())
# print(data.get_text())
# We loop again in the scraped data and extract text only
# I cleaned the data with list comprehensions to remove spaces, lines
clean_data = [data.replace('\n', '') for data in scraped_data]
clean_data_ = [data.replace(' ', '') for data in clean_data]
# Lastly we use pandas to create a csv file for later use!
data_2_csv = pd.DataFrame(clean_data_, columns=['column'])
data_2_csv.to_csv('jumia_deals', index=False, mode="a")
print(data_2_csv)
""" Print statements are for testing..."""
It's a nested for loop that we used here! That's it, you can use this code since it's MIT Licenced and customise to your needs. There are things you could implement like threading, time and memory-efficient data structures to have great results.
✔ Watch Video Implementation
If you enjoyed the article, share it, subscribe and comment for love ❤
Ronnie Atuhaire 😎