




Table of contents
In a bid to stay connected to one of the biggest writeathon I have ever come across, I decided to scrape all the four hashtags involved to see what the best tech writers have to offer.
When I was about to scrape(the hard way), I realised I could call the same information the way Hashnode does via an API call that keeps updating and populating pages through an infinite scroll.
In this article series, we shall learn to get all the blogs (title, name, domains, count, JSON data etc) for the different tech writers and also dynamically see particular blogs under any hashtags on Hashnode.
🌟 Intro
If you have no idea about this epic writeathon that has about a 17,000 USD pool prize, visit this article for more information.
After chrome inspection, I found out that they are basically using ajax calls to fetch data (if I am not mistaken). I started by enabling XML HTTP logs and in the chrome dev tools preferences;
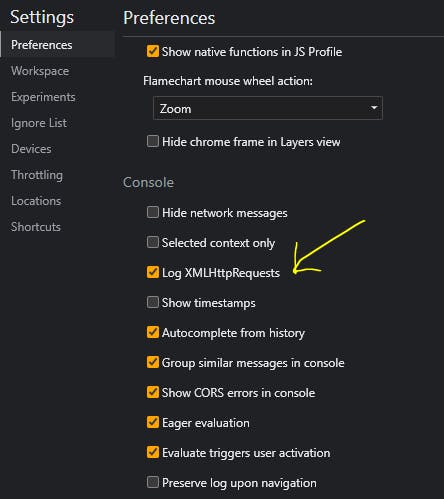
🌟 What are XMLHttp Requests ?
(XHR) objects are used to interact with servers. You can retrieve data from a URL without having to do a full page refresh. This enables a Web page to update just part of a page without disrupting what the user is doing. XMLHttpRequest is used heavily in AJAX programming.
So when we perform an infinite scroll when we have inspected for example; THW Web-Apps Hashtag, you can see the logs here under the Fetch/XHR filter tab
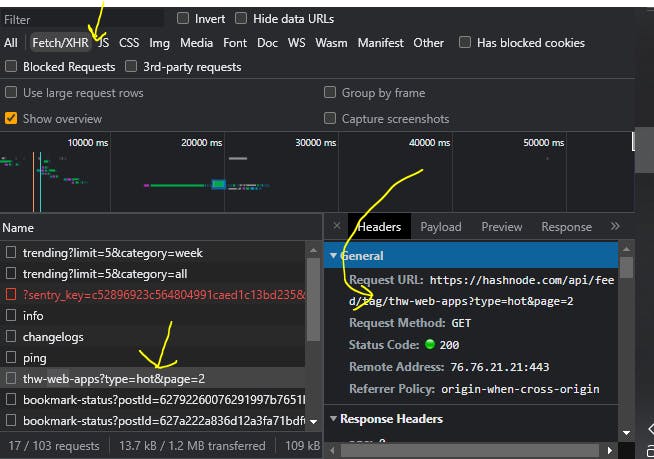
Having understood that, let's create a python package that we shall later deploy to PyPI in the subsequent articles in this mini-series.
🌟 The Code
Let's get started, you create a file and name it anything. I will call mine thw.py.
Import the necessary modules
import requests
from progress.bar import ChargingBar
import json
pip install progress requests at the same time if you don't have them.
Now, because of indentation & other related concerns, add this class under. Refer to comments for explanation and I will also explain the main details later;
# Create The Hashnode Writeathon class (THW)
class THW:
# Initialise the class constructor
def __init__(self, url):
self.api_url = url
# Other optional instance variables
self.possible_urls = []
self.post_list_count = []
self.posts = []
self.total = 0
# Connecting to the API
def connect(self):
# Append the init url
self.possible_urls.append(self.api_url)
for page in range(0,1000):
# Let's dynamically create the URLS for our get requests
next_urls = self.api_url + '?page=' + str(page)
self.possible_urls.append(next_urls)
try:
for idx, url in enumerate(self.possible_urls):
response = requests.get(url,
headers={"Accept": "application/json"},
)
data = response.json()
blog_posts = data['posts']
# Get count of the posts on that page
post_count = len(blog_posts)
# Update our counter container
self.post_list_count.append(post_count)
# Adding progress bar
bar = ChargingBar(f"---- Getting Page {idx} Posts ---", max=post_count)
for data in blog_posts:
# Get summary data from each post
article_title = data["title"]
pub_title = data["publication"]["title"]
domain = data["author"]["username"]
article_slug = domain + ".hashnode.dev/" + data["slug"]
date_added = data["dateAdded"]
self.posts.append((article_title, pub_title, article_slug, date_added))
bar.next()
bar.finish()
# Break from the for loop if no posts on that page
if post_count == 0:
break
return "-- SUCCESSFULLY GOT ALL THE POSTS : SUMMARY IS READY ---"
except Exception as e:
return f"ERROR :: {e}"
Woah, what's happening? Well, w just created a re-usable model of python code and we shall test it later.
I called my class THW - The Hashnode Writeathon and the constructor (__init__ ) takes in the api_url and this means every time we are creating an instance of this class, we pass in a valid API URL.
The connect() method starts by generating 1000 URLS for us that we can loop through to get the blog post data and all related information about the posts under that particular hashtag.
We then loop through the created URLs getting the information we need which we can get using dictionary CRUD operations.
The post_count variable is really vital as it helps us get the number of posts present on that particular page at a time, we then use it to break from the loop if no posts are found on that particular page meaning it is the last page for now.
The post_list_count records all the post_count in a list that we shall later use to determine the number of posts in that particular hashtag.
That's it... so let's test by creating another file in the same folder.
from thw import THW
URL = 'https://hashnode.com/api/feed/tag/thw-web-apps'
web_apps = THW(URL).connect()
print(web_apps)
That URL was determined from the inspection we did. So, if you run the file;

That's it for now. In the next post in this series, we shall create other methods that will help us retrieve a summary of the posts, and current blog count, dumping to a JSON file and pushing to PyPI.
🌟 Conclusion
Once again, hope you learned something today from my little closet.
Please consider subscribing or following me for related content, especially about Tech, Python & General Programming.
You can show extra love by buying me a coffee to support this free content and I am also open to partnerships, technical writing roles, collaborations and Python-related training or roles.
 📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂
📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂