




Following the first blog I wrote in this mini-series, we are going to get the count, summary and JSON data from the script we wrote.
If you missed part one, please read it here and give me your feedback. Glad you are here;
So In the same file, we created (thw.py), let's add the following methods under the same class. Let's begin by getting the count;
def count(self):
self.connect()
total_ = 0
# print(self.post_list_count)
total = [total_ := total_ + x for x in self.post_list_count][-1]
return f"There are currently {total} posts written!"
So we define a method called count() that will return the number of posts submitted so far under a particular hashtag.
The total line has a list comprehension and I am using the walrus operator (:=) which basically helps me create a variable in the middle of an expression which will return a list of subtotals. We then get the last in that element (final total).
Read more about the walrus operator in the article I wrote sometime.
So if we add this to our test file to get the results.
from thw import THW
URL = 'https://hashnode.com/api/feed/tag/thw-web-apps'
web_apps = THW(URL).count()
print(web_apps)
Output;

We see that we get 205 posts by the time of writing this article with this exclusive.
When we compare our results with the real hashtag count;
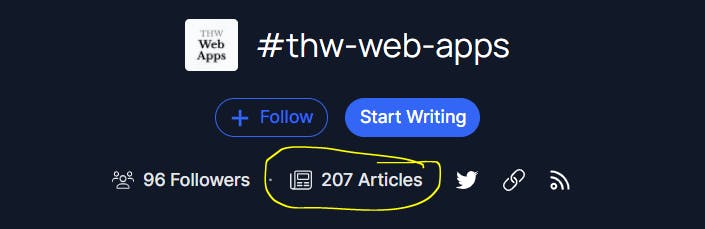 We are short by only 2 posts, probably these are being called from another API or it's an API update issue but so far so good.
We are short by only 2 posts, probably these are being called from another API or it's an API update issue but so far so good.
Let's get all the posts now. Create another instance method all_posts().
def all_posts(self):
self.connect()
print(self.posts)
for idx, post in enumerate(self.posts):
print(idx, post)
Note: All these methods depend on connect() and that's why we have to call it first.
So loop through the posts attaching an index with enumerate() function.
In our test file;
from thw import THW
URL = 'https://hashnode.com/api/feed/tag/thw-web-apps'
web_apps = THW(URL).all_posts()
print(web_apps)
The above will return a tuple of posts.

Finally, let's write that info to a JSON file for later usage or creating your own API.
def dump_json(self):
self.connect()
blog_dict = {"posts": self.posts}
blog_json = json.dumps(blog_dict)
with open("main.json", "w+", encoding="utf-8") as file:
json.dump(blog_json, file, ensure_ascii=False)
print("--- File Created Successfully ---")
In the above file, we create a dictionary first of the list of posts for easy dumping to JSON. We write the JSON data to main.json file.
In our test file;
from thw import THW
URL = 'https://hashnode.com/api/feed/tag/thw-web-apps'
web_apps = THW(URL).dump_json()
print(web_apps)
The above should create a main.json file.
Now let's test count() with a different hashtag; (web-3)
Just change the test file to;
from thw import THW
URL = 'https://hashnode.com/api/feed/tag/thw-web3'
web_three = THW(URL).count()
print(web_three)
Output at the time of writing;

And on Hashnode
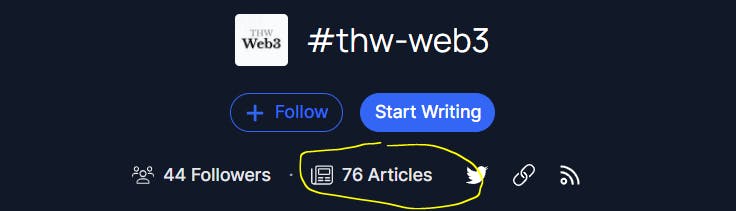
You could also try the other two APIs. See how I get them from my first part in this series by loading them in the network tab.
If you are lazy;
🚀 Cloud Computing API
🚀 Mobile Apps API
That's it for now, we shall re-package this and push it to PyPI for distribution in the next article.
Vist repo for full code.
🌟 Conclusion
Once again, hope you learned something today from my little closet.
Please consider subscribing or following me for related content, especially about Tech, Python & General Programming.
You can show extra love by buying me a coffee to support this free content and I am also open to partnerships, technical writing roles, collaborations and Python-related training or roles.
 📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂
📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂