




Table of contents
Hey 👋, welcome here! Today, we are scraping fresh crypto jobs using only Beautiful Soup & Requests libraries.
There are a couple of reasons why you would want to scrape a job board. You can use this data for job analysis, job applications, job referrals or create your own job board from an existing board by constantly and dynamically pulling the latest jobs and details from the former.
🔸 The Code
Let's not waste time:
pip install requests
pip install beautifulsoup4
Read documentation if you encounter errors installing BS4 .
Create a new py file & import modules.
import requests
from bs4 import BeautifulSoup
Now before we continue, let's head over to the Crypto Job-board and do some inspection.
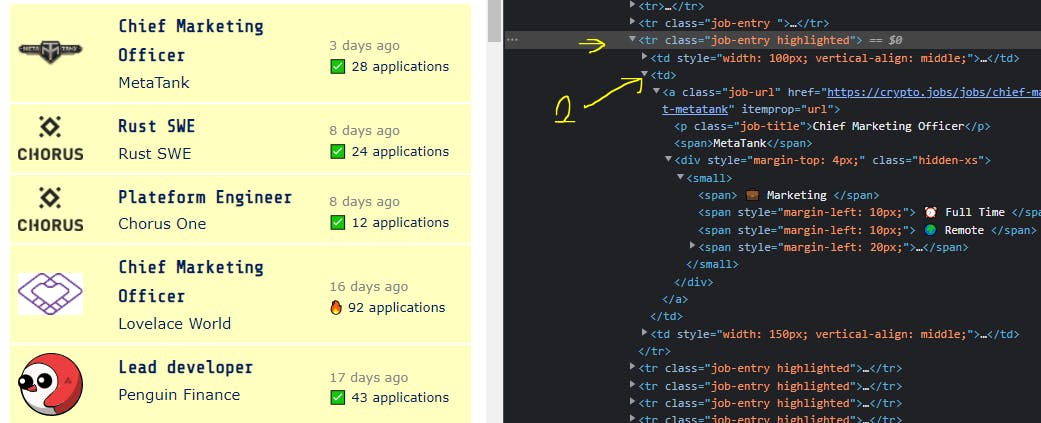 From the above snip, we realise that our data resides under
From the above snip, we realise that our data resides under tbody > tr in a second td tag.
We now inspect to see how the page loads job data from the next pages. We see that a page number query is used in routing.
For example, the second page would be https://crypto.jobs/?page=2
With that in mind, let's create a list of all the pages that we need using for loop .
urls = []
# Since we are only scraping the first 15 pages
page = [num for num in range(1,16)]
for num in page:
url = f"https://crypto.jobs/?page={num}"
urls.append(url)
Now, let's add our main code. Please find an explanation of each statement in the comments.
# We loop through each URL scraping its content
for url in urls:
# Initiate an GET HTTP request
response = requests.get(url)
# Create an HTML Parser from the response (200)
soup = BeautifulSoup(response.content, 'html.parser')
# Get the table rows that contain our data
data_row = soup.find("tbody").find_all("tr")
# Create a temp storage for each job page data
job_pages = []
# loop through the table rows
for row in data_row:
# Selecting the second 'td' tag
job_data = row.select_one(":nth-child(2)")
# Let's try getting text from non-None types data
try:
job_pages.append(job_data.get_text().strip())
except:
pass
# Print individual job data
for job_page in job_pages:
print(job_page.strip())
When we run the above code, we get;
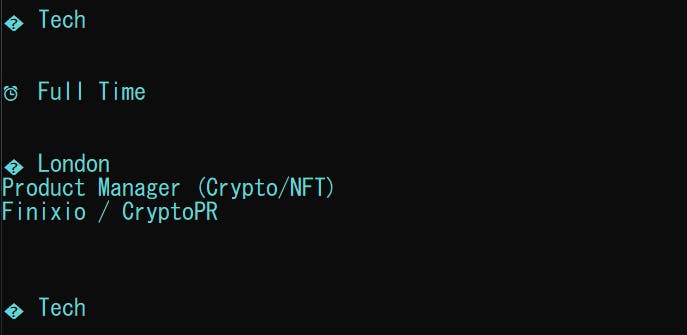
Challenge: Clean that data and remove white spaces and emojis. You can go an extra step and dump it in a CSV file. You can refer to my article here for help.
GitHub Repo
🔸 Conclusion
Once again, hope you learned something today from my little closet.
Please consider subscribing or following me for related content, especially about Tech, Python & General Programming.
You can show extra love by buying me a coffee to support this free content and I am also open to partnerships, technical writing roles, collaborations and Python-related training or roles.
 📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂
📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂