




Hey there 👋, welcome here! Have you ever wanted to scrape multiple websites and you don't have the time to wait for the scraper to get through each website URL which will, in turn, increase the execution and waiting time?
Well, we can reduce the time drastically with asynchronous programming and libraries and today, we shall be using python grequests to achieve this.
I will be writing about the aiohttp library use case sometime later!
🔸 What is Asynchronous Programming?
Asynchronous programming is a characteristic of modern programming languages that allows an application to perform various operations without waiting for any of them.
Consider a traditional web scraping application that needs to open thousands of network connections.
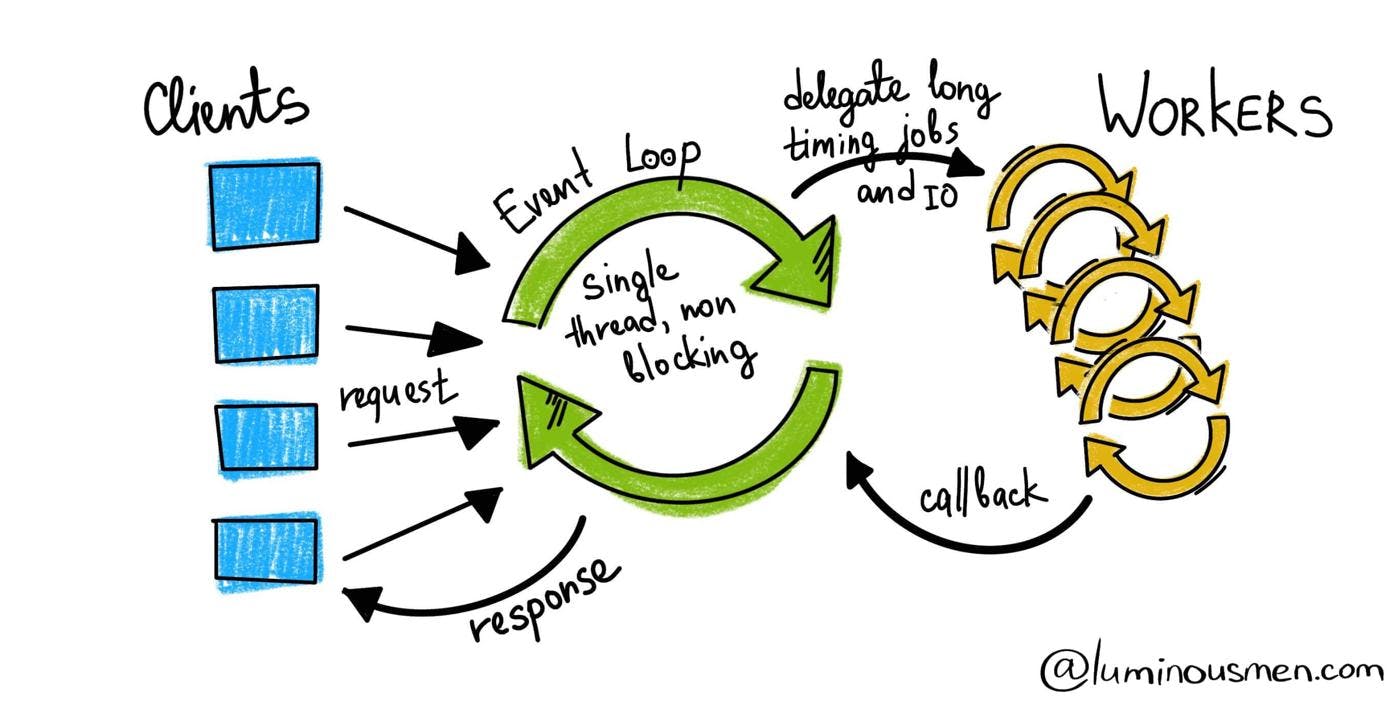
We could open one network connection, fetch the result, and then move to the next one iteratively. This approach increases the latency of the program. It spends a lot of time opening a connection and waiting for others to finish their bit of work.
Asynchronous programming relies on a non-blocking input and output (I/O) protocol. When one request fails, it has no effect on another request. And the program can move to another task before finishing the last.
🔸 Async Vs Sync
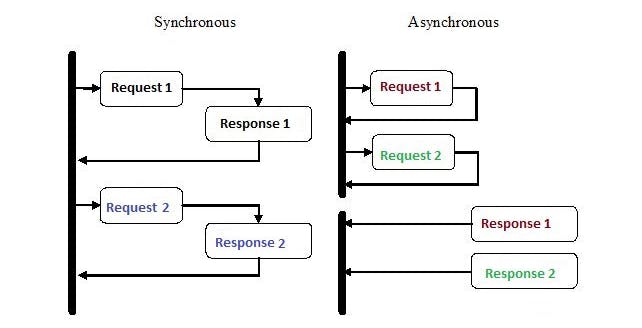
Synchronous programs are straightforward: start a task, wait for it to finish, and repeat until all tasks have been executed.
This is the method I have been using in my previous web scraping tutorials and articles. However, waiting wastes valuable CPU cycles.
 Today, we will implement asynchronous web scraping using python. In order to show the difference between the synchronous and the asynchronous counterpart, we will implement both the codes and try to see the execution time difference.
Today, we will implement asynchronous web scraping using python. In order to show the difference between the synchronous and the asynchronous counterpart, we will implement both the codes and try to see the execution time difference.
🔸 Code Comparison
Let's implement Synchronous programming first;
Let's create a sync_py.py file and add this code:
### Importing libraries ###
import requests
import time
### Starting the timer ###
start_time = time.time()
### Our URL List ###
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://hashnode.com',
'https://producthunt.com']
### Getting our Requests With ###
for link in urls:
req = requests.get(link)
print(f"[+] Getting Link [+] {link} === {req} ")
### End Time ###
end_time = time.time()
print("It took --- {} seconds --- for all the links"
.format(end_time - start_time))
The above code basically does a GET HTTP request and prints a status response to the console. As we can see, I have also used time.time() to get the execution time differences from when the program starts and ends.
When we run the above code: we get;
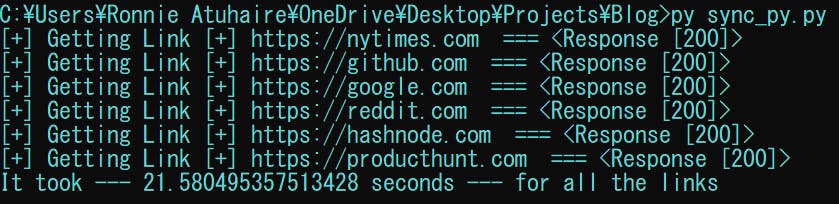 So it took about 22 seconds to finish!
So it took about 22 seconds to finish!
Now let's implement the same code but this time with grequests.
GRequests allows you to use Requests with Gevent to make asynchronous HTTP requests easily.
pip install grequests
create a new asynchro_py.py file and add this code:
### Importing libraries ###
import grequests
import time
### Starting the timer ###
start_time = time.time()
### Our URL List ###
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://hashnode.com',
'https://producthunt.com']
### Getting our Requests With ###
our_requests = (grequests.get(link) for link in urls)
responses = grequests.map(our_requests)
for link in urls:
for response in responses:
print(end="")
print(f"[+] Getting Link [+] {link} === {response} ")
### End Time ###
end_time = time.time()
print("It took --- {} seconds --- for all the links"
.format(end_time - start_time))
In the above code, the main thing we did (added) was creating agrequests generator and map it to get our responses.
So when we run the above file; We get;
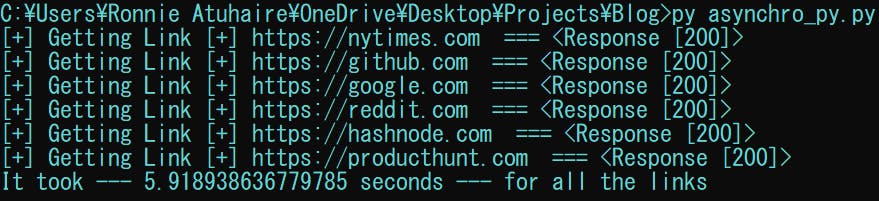
So we see that the time has drastically reduced from over 20 seconds to just 5! With asynchronous programming, you have the power to utilise the CPU Cycles and other network features.
GitHub Repo 🚀
🔸 Summary
In this blog, we looked at how asynchronous web scraping can help us in drastically reducing the execution time of web scraping tasks.
You can read more about GRequests here
There are other libraries like aiohttp, asyncio, FastAPI etc which we shall see some time to come.
🔸 Conclusion
Once again, hope you learned something today from my little closet.
Please consider subscribing or following me for related content, especially about Tech, Python & General Programming.
You can show extra love by buying me a coffee to support this free content and I am also open to partnerships, technical writing roles, collaborations and Python-related training or roles.
 📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂
📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂