




Hey there 👋, welcome here! Having looked at Asynchronous Web Scraping With Python GRequests, today we are using a different approach as I promised; We are using aiohttp
Open that article in a new tab because I will be referencing to it.
So we shall be using two major modules and one comes with the standard python library.
🔸 aiohttp
It is a library for building web-client and web-server using Python and asyncio.
#Ad
ScraperAPI is a web scraping API tool that works perfectly with Python, Node, Ruby, and other popular programming languages.
Scraper API handles billions of API requests that are related to web scraping and if you used this link to get a product from them, I earn something.
🔸 asyncio
It is a Python 3’s built-in library. This means it’s already installed if you have Python 3. Since Python 3.5, it is convenient to work with asynchronous code.
asyncio stands for Asynchronous Input-Output. This is a very powerful concept to use whenever you work IO. Interacting with the web or external APIs such as Telegram makes a lot of sense this way.
Let's not waste time and import the necessary modules
import aiohttp
import asyncio
from timeit import default_timer
You may want to pip install aiohttp before you continue if you don't have it.
We define the same and exact URLs we used in our synchronous file in this article;
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://hashnode.com',
'https://producthunt.com']
Now create a normal function that has async pre-appended to it lie this; async def main(): and add the following code underneath which I will explain later on;
This function will help us fetch the HTTP Status responses and we shall later define a main() one that will await the results from this function and aid us in creating and running the event loop.
async def fetch_status():
start_time = default_timer()
async with ClientSession() as session:
for url in urls:
async with session.get(url) as response:
print(f"[+] Getting Link [+] {url} === {response.status} ")
time_elapsed = default_timer() - start_time
print("It took --- {} seconds --- for all the links"
.format(time_elapsed))
In order to have an asynchronous function, we use the async keyword.
default_timer() : This will return the default time when executed.
We open a client session with a with keyword that automatically handles the opening & closure of the session for us and then we loop through the URLs to get the response status.
We later calculate the time that has elapsed in doing so.
Now let's create the main() function since it is required and very essential and it will basically call fetch_status().
async def main():
await fetch_status()
Now if everything is good, we create the event loop and run our file;
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
To run an async function (coroutine) you have to call it using an Event Loop. Event Loops: You can think of Event Loops as functions to run asynchronous tasks and callbacks, perform network IO operations, and run subprocesses.
Running the above script produces;
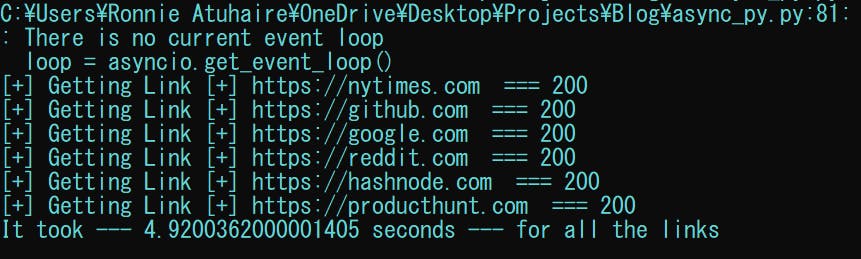 At the time of writing, I am using
At the time of writing, I am using Python 3.10 and yours could be perfect (between 3.5-3-8) and you may not see those depreciation warnings above.
But if you don't want to see them when you run your file, you can add this on top;
import warnings
warnings.filterwarnings("ignore")
So our entire file is;
import aiohttp
import asyncio
from timeit import default_timer
from aiohttp import ClientSession
import warnings
warnings.filterwarnings("ignore")
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://hashnode.com',
'https://producthunt.com']
async def fetch_status():
start_time = default_timer()
async with ClientSession() as session:
for url in urls:
async with session.get(url) as response:
print(f"[+] Getting Link [+] {url} === {response.status} ")
time_elapsed = default_timer() - start_time
print("It took --- {} seconds --- for all the links"
.format(time_elapsed))
async def main():
await fetch_status()
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
🔸Notes & Resources
That's it! Find the GitHub repo here.
📌 Read my first article here.
📌 asyncio official docs
📌 aiohttp official docs
🔸 Conclusion
Once again, hope you learned something today from my little closet.
Please consider subscribing or following me for related content, especially about Tech, Python & General Programming.
You can show extra love by buying me a coffee to support this free content and I am also open to partnerships, technical writing roles, collaborations and Python-related training or roles.
 📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂
📢 You can also follow me on Twitter : ♥ ♥ Waiting for you! 🙂